|
Plan de l'article |





|
Citer l'article |
|
Carlino, V., Pignard-Cheynel, N., Loubère, L., Ricaud, B., & Aspert N. (2021). Naviguer dans les traces numériques sur Twitter. Retour sur la conception d’un dispositif de cartographie de données à destination de journalistes. Revue Intelligibilité du numérique, 2|2021. [En ligne] https://doi.org/10.34745/numerev_1707 |
Résumé : Cet article offre un retour d’expérience d’une recherche appliquée pluridisciplinaire pour concevoir un outil d’exploration et de cartographie de données issues de Twitter à destination des journalistes. L’approche privilégie l’observation et la compréhension des usages des journalistes et une projection d’intégration du logiciel dans leurs pratiques et les routines quotidiennes. Trois scénarios d’usages sont développés, rendant compte d’une diversité d’appropriation de l’outil. Ils soulignent l’intérêt de penser une interface favorisant la compréhension par l’utilisateur des opérations réalisées sur les données, mais également la nécessité que les usagers disposent d’une culture numérique minimale pour produire des contenus éditoriaux fondés sur l'exploitation des traces numériques.
Mots-clés : cartographie, traces numériques, journalisme, plateformes de réseaux sociaux, Spikyball sampling.
Abstract : This article provides feedback on a multidisciplinary and applied research project to design a data mapping and exploration tool on Twitter for journalists. The approach focuses on the observation and understanding of journalists' uses and a projection of the integration of the software in their daily practices and routines. Three use cases scenarios are explored, reflecting the diversity of the tool's appropriation. Each of them underlines the interest in designing a transparent interface that favors the user's understanding of the operations performed on the data, but also the need for users to have a minimal digital culture to produce journalistic content based on these digital traces.
Keywords: cartography, digital traces, journalism, social network platforms, Spikyball sampling.
Introduction
Cette contribution revient sur la conception d’un logiciel de cartographie de données issues des réseaux socionumériques à destination de journalistes. Réalisée dans le cadre d’une collaboration interdisciplinaire, associant des chercheurs de sciences de l’information et de la communication d’un côté et de la science des réseaux de l’autre, cette recherche vise à explorer l’écosystème des discussions en ligne et plus particulièrement de sujets controversés sur Twitter dans une perspective appliquée aux usages journalistiques. Elle s’inscrit dans la volonté de cartographier les différents groupes d’utilisateurs qui participent à rendre visibles des débats, notamment dans le cadre de la diffusion de fausses informations. Menés dans le cadre du projet Social Networks Architectures of Disinformation (SAD), grâce au financement de l’Initiative pour l’innovation dans les médias (IMI), ces travaux ont abouti à la réalisation d’un prototype reposant sur la cartographie de comptes Twitter actifs dans les controverses. L’article se focalise sur le deuxième volet du projet de recherche consacré à l’application et l’adaptation de ce prototype aux usages des journalistes. Nous proposons de revenir sur le processus de conception de l’outil pour rendre compte de la réflexion sur les données numériques qui a émergé de la collaboration interdisciplinaire, mais également de la manière dont la conception a intégré des journalistes afin de recueillir des paroles sur les pratiques professionnelles et d’observer la diversité des usages du prototype.
C’est donc la co-conception interdisciplinaire d’un outil de cartographie de données numériques qui constitue l’objet de cet article. Nous interrogeons la manière dont les données des réseaux socionumériques s’inscrivent dans le travail de recherche d’information des journalistes et dans quelle mesure elles peuvent être utilisées en tant que sources. Cette démarche nourrit une réflexion sur les données fournies par l’API de Twitter, utilisées pour produire les cartographies. Contrairement à d’autres outils existants, le logiciel SAD repose sur des comptes et leur interconnexion plutôt que sur les contenus des tweets. L’enjeu réside donc à la fois dans ce qu’inclut ou non la méthode de collecte, mais aussi dans la présentation visuelle des informations. Pour les journalistes, la pertinence des informations repose dans ce jeu entre le paramétrage de la récolte de données et la navigation dans l’interface qui présente ces données. Ces deux dimensions ont structuré l’enquête de terrain constituée d’un focus group et d’entretiens individuels avec cinq journalistes de la RTS choisis pour la diversité de leur profil et leur intérêt et connaissance des réseaux socionumériques. Ce travail empirique a permis de recueillir des projections d’usages vis-à-vis de leur pratique professionnelle, ainsi qu’à observer leur appropriation du prototype.
La démarche qui guide cette contribution n’est pas celle d’une observation des pratiques professionnelles et des méthodes de travail des journalistes au sein d’une rédaction. Elle consiste plutôt à revenir sur un processus de conception d’un support à l’activité journalistique, reposant sur un travail interdisciplinaire des données et l’intégration d’usagers, dans une démarche inspirée de la sociologie de l’innovation et des cadres socio-techniques (Flichy, 2003). L’inclusion de journalistes sert la double perspective de recueil de pratiques professionnelles vis-à-vis des réseaux socionumériques qui nourrissent l’implémentation de nouvelles fonctionnalités, ainsi que d’observation des usages du prototype en train de se faire pour procéder à des ajustements. La documentation de ce processus de co-conception à l’interface des sciences des réseaux, du journalisme et des pratiques professionnelles interroge l’attribution de valeur informationnelle des traces numériques. Nous montrons que celle-ci s’effectue notamment à travers l’appropriation par les usagers de notions techniques inhérentes à la récolte de données et à la science des réseaux, tout en s’inscrivant dans des usages préexistants des réseaux socionumériques dans le cadre de l’activité journalistique.
Les traces numériques dans les usages journalistiques
Les réseaux socionumériques dans les pratiques journalistiques
L’outil développé dans le cadre de ce projet entend favoriser le recours aux réseaux socio-numériques (RSN), comme source et terrain, par les journalistes de la Radio-Télévision Suisse (RTS), voire au-delà. La littérature scientifique, qui documente depuis une dizaine d’années l’appropriation des RSN par les journalistes, offre un panorama de la diversité des usages et de leur intégration différenciée dans les pratiques professionnelles, tout en en soulignant également les limites. Notre travail concerne essentiellement Twitter, réseau largement privilégié par les journalistes depuis ses débuts, en ce qu’il favorise la prise de parole directe, l’interaction et la discussion, dans une temporalité de l’immédiateté et dans un espace en grande partie public. Et ce contrairement à Facebook dont les espaces sont davantage fermés et les contenus moins orientés vers l’information et les médias (Bruns, 2018, 14).
Si les utilisations de Twitter par les journalistes sont très diversifiées, nous nous intéresserons ici aux analyses portant sur un usage « en amont » du travail journalistique, idéalement comme source première d’identification de sujets pertinents à traiter, voire comme terrain d’analyse à part entière pour produire des enquêtes journalistiques sur le déploiement de controverses par exemple. Dans ses intentions, l’outil développé entend se distinguer d’un ensemble d’usages qui a marqué les débuts du journalisme numérique, avec une volonté de réseautage et d’entretien d’un « club » fermé, constitué pour beaucoup de (jeunes) journalistes acculturés au numérique (Mercier, 2012).
Le prototype SAD est davantage envisagé comme un apport au travail journalistique de recherche d’informations, de sources mais aussi de compréhension du fonctionnement des RSN envisagés alors comme terrains d’observation à part entière. On retrouve l’idée d’un outil de recherche au service de l’enquête, identifié dans les pratiques journalistiques dès la fin des années 2000 (Ahmad, 2010). Twitter y apparaît comme une source pertinente pour trouver des idées de sujets ou des sources, par exemple dans le domaine économique et financier (Lariscy et al., 2009). La palette des usages est toutefois large et ce recours à Twitter peut se révéler plus minimaliste et illustratif, par exemple dans la recherche d’informations, de contenus et de citations, venant enrichir des articles (via ce que l’on appelle communément les « tweets embedded ») (voir notamment Broersma, Graham, 2012 et 2013 ; Bane, 2017). C’est notamment le cas pour la couverture de certains événements ou thématiques impliquant des personnalités publiques très actives sur Twitter (politique, people, sport, etc.). Des outils, comme « Tweetdeck », favorisent ces usages avec des fonctionnalités de veille avancées. Pourtant, cette opportunité d’explorer Twitter à des fins journalistiques reste assez superficielle et limitée selon Lawrence (2015), la plupart des journalistes utilisant davantage la plateforme dans une logique de diffusion de leur contenu. L’enjeu de notre projet est donc d’identifier des journalistes susceptibles de trouver un intérêt à un outil d’exploration des conversations sur les RSN pour produire du contenu, mais également ayant les connaissances minimales de base du fonctionnement, du vocabulaire et des principes régissant ces plateformes.
Cette compétence, que l’on peut associer à une forme de « digital literacy » est progressivement entrée dans les salles de rédaction, parfois à la faveur de profils de journalistes plus spécialisés (en particulier les datajournalists, mais également les community managers). De même, la préoccupation croissante liée à la désinformation et aux « fake news » circulant sur les RSN a suscité de nouvelles pratiques journalistiques pertinentes pour notre projet. Pensons par exemple à la nécessité de pouvoir identifier un compte Twitter ou une source, mais aussi plus largement aux pratiques de vérification des faits (Weaver, Willnat, et Wilhoit, 2019), ici aussi facilitées par des outils spécifiques (Brandtzaeg, Følstad, et Chaparro Domínguez, 2018). C’est le cas encore de l’OSINT (open source intelligence) et du data-journalisme qui conduisent les journalistes à considérer les réseaux socionumériques comme des terrains d’analyse voire des sujets à part entière et non comme des éléments illustratifs et secondaires.
Il y a donc un enjeu important d’accompagnement des journalistes dans leur appropriation de l’outil, mais également plus largement dans la compréhension et la connaissance des mécanismes à l'œuvre dans les RSN. A cela s'ajoute la compréhension de la manière dont les données sont récoltées et fabriquées. Qu'ils soient considérés comme avancés ou « grand public », les outils de recherche façonnent des traces numériques qui ne peuvent pas prétendre représenter Twitter dans sa globalité. L'enjeu pour les journalistes est double : il s'agit de comprendre comment ces traces sont fabriquées et récoltées pour éviter des généralisations abusives d'une part ; et d'être en capacité d'avoir la maîtrise de ces paramètres pour pouvoir les expliquer au public d'autre part. Plusieurs questionnements, au centre de la démarche de conception de l’outil SAD en découlent : comment rendre autonomes les journalistes dans la récolte et l'interprétation de données à propos de controverses sur Twitter ? Dans quelle mesure la récolte de données est-elle reproductible ? Selon quels critères les journalistes accordent-ils une valeur journalistique aux traces ?
Donner du sens aux traces numériques
L'utilisation des RSN ne se limite pas au contenu de ce qui y est publié, mais intègre des traces qui sont autant de renseignements sur l'utilisateur pouvant être interprétés « avant même qu'un message-cadre vienne les “intentionnaliser” par une métacommunication » (Merzeau, 2013). Ces traces sont travaillées en retour par la plateforme à travers son API qui propose aux développeurs un accès à la base de données de ses archives. Cette interface, tout comme le formatage de ces données, n’est pas prévue pour des recherches journalistiques, mais pour des tâches de webmastering ou de community management. Ainsi, au-delà des compétences en programmation que nécessite l'interrogation de l'API, la forme des données accessibles correspond à des choix de formatage effectués en amont par l’entreprise. Ces caractéristiques n’influent pas seulement sur l’aspect des données, mais aussi sur les requêtes possibles. Les temporalités et les quantités accessibles étant limitées, elles imposent des stratégies qui se justifient d’un point de vue informatique, mais qui peuvent entrer en confrontation avec la compréhension journalistique du réseau.
Ce processus tend à séparer les supports matériels sur lesquels sont consultés les résultats et le calcul réalisé sur ces données. Au prisme de l'API, les tweets perdent l'interface graphique qui permet leur inscription et leur réception au profit de chaînes de caractères et de données statistiques. L'approche techno-sémiotique souligne les problèmes de cette séparation pour la consultation et l'analyse des archives du web (Bottini, Julliard, 2017). Dans le cas présent, l'usage journalistique des traces numériques implique de revenir sur leur compréhension : ce qu'elles représentent et les limites de leur interprétation en dehors de leur contexte de production et de réception. S'ajoute ensuite l'enjeu de leur représentation sous une forme différente de celle de l'interface du réseau social, afin de donner accès à une vision plus globale du réseau, c'est-à-dire qui dépasse l'espace visible des timelines et des résultats de recherche et qui repose sur les archives de la plateforme.
Cette question correspond à une définition du numérique en tant que milieu, c’est-à-dire employé pour désigner des activités qui le mobilisent « pour d’autres finalités que le calcul » (Bachimont 2017, 388). En effet, les activités sociales d’échange et de partage de contenus mesurées et calculées par Twitter constituent la base d'un travail d'interprétation journalistique dont la finalité dépasse le cadre computationnel. Dans cette perspective, la méthode de recherche mise au point intègre des journalistes intéressés par le numérique, afin d'explorer avec eux l'exploitation des traces numériques pour la conception de contenus éditoriaux.
Méthode
Le travail autour du projet SAD a débuté en 2019, en réponse à l’appel à projets de l’Initiative for media innovation intitulé : « Aider les médias à lutter contre la désinformation et à rétablir la confiance du public ». L’objectif poursuivi durant les 12 mois de ce projet était de concevoir un outil capable d’exploiter la structuration des réseaux socionumériques (connexions inter-comptes) afin de cartographier les activités de circulation de l’information, à des fins journalistiques. Pour mener à bien cette recherche, un collectif s’est construit associant des chercheurs en sciences des réseaux, des chercheurs en sciences de l’information et de la communication et un partenaire média, la Radio-Télévision Suisse (RTS). Cette interdisciplinarité devait aboutir à l’élaboration d’un prototype automatisant les recueils et traitements des données issues des réseaux socionumériques sous forme de cartographie interactive venant en appui au travail journalistique.
Le second volet de ce projet (février 2021 - janvier 2022), sur lequel se fonde majoritairement cet article, a consisté à faire évoluer le prototype vers un outil permettant un degré d’autonomie avancé aux journalistes dans l’exploration des réseaux. Cette transition de la « recherche et développement » vers une « recherche appliquée » s’est accompagnée d’une évolution méthodologique avec le souhait d’intégrer les futurs usagers de l’outil. C’est ainsi que cinq journalistes de la RTS ont été associés à cette phase du projet, à travers des focus groups et des entretiens individuels qui devaient permettre de mieux saisir leurs usages dans une visée d’évolution des fonctionnalités de l’outil. Le recrutement des journalistes s’est fait sur la base du volontariat et de leur intérêt déclaré pour les RSN. L'équipe de journalistes se compose de trois femmes et deux hommes, spécialisés dans l'animation radio, la production de podcasts, les reportages télévisés et la production d'articles écrits pour le portail RTS Info. Leurs attentes et niveaux d’expertise sur les outils et données numériques sont volontairement hétérogènes de manière à envisager plusieurs profils d’usages, afin d'éviter de restreindre l'accès à l’outil aux seuls journalistes de données.
En juin 2021, un premier focus group a réuni les 5 journalistes autour d’une présentation et une prise en main de l’outil. L’objectif était de mieux cerner leur utilisation des réseaux socionumériques dans un cadre journalistique, mais également leurs attentes par rapport à l’outil et la manière dont il pourrait s’intégrer dans leurs routines.
Environ un mois plus tard et après avoir implémenté les évolutions mises en évidence, des sessions individuelles ont été réalisées avec chacun d’entre eux. L’objectif de ces échanges était d’approfondir les utilisations possibles de l’outil avec un test grandeur réelle portant sur un sujet propre au journaliste. Du côté de l’équipe de recherche, ce fut l’occasion également d’adopter une approche compréhensive, en guidant les journalistes dans leurs recherches et explorations, ainsi qu’en expliquant les processus en action dans le but d’observer les formes d’appropriation de l’outil. Cette démarche associant les futurs usagers, des chercheurs de sciences informatiques et d’autres des sciences humaines et sociales, visait à éviter l’écueil techniciste d’un outil développé en dehors de la compréhension de ses futurs usages, tant légitimes que mineurs ou décalés.
Caractéristiques de l’outil d’exploration des communautés Twitter
Sur Twitter, les activités de publication de contenus tissent des liens entre des comptes à travers des interactions instrumentées (following, réponse, like ou retweet) qui font appel à une posture et des usages différents. Le présupposé du logiciel SAD est que la mise en visibilité des données de relations inter-comptes peut produire des informations pertinentes sur l'adhésion ou non aux propos relayés. Réalisée à partir de l’activité de (re)publication des utilisateurs, cette interconnexion de profils est imperceptible des utilisateurs qui n'ont accès qu'à leur timeline, c’est-à-dire à une succession de tweets organisés selon un ordre chronologique et algorithmique. En se fondant sur les données issues de l’API, SAD trace des liens entre les profils en fonction de leurs flux entrant et sortant de tweets, retweets et réponses. Son fonctionnement souligne l’intérêt pour le journalisme de travailler à partir de données issues de l’activité de comptes d'utilisateurs plutôt que des contenus publiés en ligne.
L’approche Spikyball, au coeur de la collecte et du traitement des données
L’outil développé repose sur l'identification préalable de comptes pertinents pour l’exploration des communautés. Un journaliste intéressé par les discussions à propos d’un thème ou d’un événement sélectionne un ou plusieurs comptes de départ. Ceux-ci n’ont pas besoin d’être centraux dans la mesure où l’usager identifiera par lui-même les comptes clés du sujet exploré en fonction des paramètres qu’il juge pertinents pour la collecte et l’exploration des données (présentés autour de trois scénarios d’usage ci-après).
A partir de ce point de départ, l’explorateur fouille automatiquement l’environnement de ces comptes en suivant les retweets entre utilisateurs pour guider sa collecte et rester dans un voisinage plus ou moins proche. Étant donné sa taille, le réseau dense de connexions ne peut pas être entièrement collecté ; l’explorateur sélectionne donc aléatoirement une partie des voisins du groupe initial. Avec l’approche Spikyball (Ricaud, 2020), une probabilité plus forte de collecte est donnée aux voisins proportionnellement les plus connectés au groupe initial. Ceci permet d’orienter la collecte vers les nœuds plus centraux autour d’un thème, ainsi que les références et acteurs les plus actifs de la ou des communauté(s). La méthode est itérative : une fois que le processus de collecte a fini l’exploration des voisins directs, ceux-ci deviennent le groupe initial, exploré à son tour lors de la prochaine itération, et ainsi de suite. Cette méthode permet de récolter des comptes du réseau qui n’auraient pas été sélectionnés au premier passage du fait de l'échantillonnage aléatoire, et ce malgré leur intérêt potentiel. Sur les RSN, le nombre de nœuds augmente de manière exponentielle avec une exploration de type « snowball sampling » (Illenberger, 2012) ou « breadth-first search ». Le mécanisme de collecte de Spikyball ne suit qu’une partie des voisins à chaque étape, et favorise ainsi une collecte basée sur l’importance des nœuds (leur nombre de connexions). Par ailleurs, à tout moment, l’utilisateur contrôle le nombre d’itérations opérées.
La visualisation des réseaux collectés est intégrée à l’explorateur, et permet à l’utilisateur de mieux appréhender la façon dont s’organisent les communautés qui le constituent. L’objectif est de favoriser la formule la plus compréhensible en vue de l’interprétation des résultats. Certains programmes dédiés à la visualisation de réseaux, comme Gephi, permettent d’accéder à de nombreuses méthodes et d’en modifier les paramètres. L’approche choisie ici est de limiter les possibilités d’organisation spatiale des comptes à deux méthodes. L’une, hiérarchique, appelée « circlepack », se base uniquement sur certains attributs des comptes du réseau (sa communauté et son degré) et groupe les comptes par communautés. L'autre fait partie du groupe des « force-directed layouts » (ForceAtlas2) et met l’accent sur la force des connexions en rapprochant dans la visualisation les nœuds les mieux connectés (même s’il n’appartiennent pas à la même communauté). Afin d'apporter une lecture plus concrète des communautés, un volet lexicométrique a été ajouté à l'outil. À partir du code source d'Iramuteq (Ratinaud 2014), nous avons automatisé le calcul du vocabulaire spécifique de chaque communauté de réseau (Lebart, 1994). La visualisation finale affiche le lexique qui caractérise le plus chaque groupe.
Une interface utilisateur favorisant la transparence des paramètres de collecte et de visualisation
L’interface s’est construite dans l’interaction entre chercheurs et journalistes, avec la volonté de mettre à disposition de ces professionnels un outil exploitable et pertinent dans leur métier. Nous considérons ici que le dispositif, par les actions et interactions avec les données qu’il propose, constitue des possibilités d’actions (Verlaet, 2015). Ces affordances (Gibson, 2000) ne prennent sens que dans le contexte d’une action mêlant les caractéristiques de l’outil avec les besoins et la culture numérique du journaliste. Les fonctionnalités du logiciel ont été développées en prenant compte des pratiques existantes des journalistes sur les réseaux socionumériques et notamment l'utilisation récurrente d'outils de veille tels que ceux décrits plus haut. L'objectif n'est pas de développer un outil unique dans lequel réaliser l'ensemble de la recherche (depuis la récolte des données jusqu'à leur interprétation), mais d'ajouter des éléments supplémentaires aux traces numériques déjà connues et manipulées quotidiennement par les journalistes. De ce point de vue, le logiciel SAD est conçu comme un assistant qui permet, en fonction des besoins des acteurs et de la complexité de la tâche à réaliser, de sortir de l'interface de Twitter pour gagner en maîtrise sur les paramètres de la collecte des données et accéder à des outils de cartographie plus avancés.
Son fonctionnement repose sur la succession de plusieurs étapes volontairement réduites et réparties entre le paramétrage de la collecte d'une part et celle de la visualisation des données d'autre part. Pour chaque requête, l’utilisateur doit choisir les comptes qui servent de point de départ à l'échantillonnage. Si ces comptes sont importants, leur impact sur la collecte est toutefois réduit du fait de la méthode Spikyball, susceptible d'inclure des comptes pertinents qui n'auraient pas été repérés au préalable. Ceci encourage les utilisateurs à lancer la requête sans attendre de repérer manuellement des comptes correspondant au sujet exploré, ces derniers pouvant apparaître au fil de l'exploration de la cartographie de comptes. Ensuite, le logiciel invite à préciser les paramètres qui définissent le périmètre de la collecte des données et de leur affichage dans la cartographie. Notons que ceux-ci peuvent être modifiés tout au long de l'exploration, générant de nouveaux jeux de comptes et cartographies (appelés « runs »). Ainsi, le logiciel encourage une approche itérative, procédant par tâtonnements, ce que les tests du prototype avec les journalistes ont d’ailleurs bien mis en évidence. Ces différentes tentatives peuvent être renommées pour faciliter leur repérage ainsi que leur partage au sein d'un groupe de journalistes qui mèneraient une enquête collaborative.
L'interface de l'outil SAD est donc conçue pour donner à voir les différentes étapes du processus de collecte et de visualisation des données. Ces principes sont au cœur de l’exploration et offrent au journaliste un contrôle fin de l’outil. Le choix libre des points de départ, celui des paramètres d’exploration et la logique itérative permettent au journaliste de piloter l’exploration. De plus, l’interface a été pensée pour rendre visibles les différentes étapes du processus. Cette interaction homme-machine peut faciliter la compréhension du fonctionnement de l’outil et de ses limites. Ceci renforce la confiance et l’interprétabilité des résultats. Nous évitons ici certains écueils classiques de l’intelligence artificielle (Domingos, 2012 ; Mehrabi, 2021). L'un d'entre eux est lié aux biais cachés qui influencent les décisions de la machine sans que l’utilisateur n’en ait conscience. Si des biais existent ici, l’utilisateur, par son interaction, et par sa vision des étapes de l’outil d’exploration, sera à même de les identifier. Soulignons cependant que ceci ne sera possible que si le journaliste dispose d'une culture numérique et d'un bagage technique minimum en lien avec les données issues des réseaux socionumériques et leur APIs. Cette acculturation réside moins dans une maîtrise technique des programmes que dans la compréhension des logiques qui régissent la production de données à l'intersection de logiques sociales, de calcul et marchandes au sein desquels le journaliste s'inscrit, y compris lorsqu'il accède aux données via un outil visant à faciliter l'accès aux données tel que SAD. Cela constitue un enjeu qui sera traité dans la suite du projet. Pour l'heure, la question de la formation et, plus exactement, d'une approche compréhensive des usages a été assurée via la médiation par l'équipe de recherche lors des entretiens individuels et collectifs visant à explorer les potentialités de l’outil. Pour ce faire, les journalistes ont été rendus semi-autonomes dans leur prise en main, laissant émerger plusieurs types d'usages qui ont nourri la réflexion et l’évolution de la conception du logiciel.
Trois scénarios d’usage éclairant l’appropriation de l’outil par les journalistes
Afin d'inscrire au mieux l'outil dans les pratiques professionnelles, une étude des usages potentiels a été réalisée. La démarche de recherche visait à se détacher d’une projection idéalisée d’un usage-type. En dépassant notamment nos propres a priori de chercheurs, comme celui d'une prédominance de la cartographie de discussions, l'approche visait à accepter des conceptions pouvant paraître au premier abord décalées ou mineures.
La confrontation de l’outil au terrain a fait émerger un ensemble d’usages qui n’avaient pas été conçus en tant que tels. Ceux-ci ne concernent pas simplement des manières de réaliser une action : ils englobent des représentations et des situations dans lesquelles les journalistes se projettent pour déterminer la plus-value de SAD. Ces « scénarios » incluent la définition de paramètres spécifiques, l’interprétation des cartographies de données et sont orientés vers une finalité qui s’inscrit dans des pratiques professionnelles qui dépendent des intérêts et spécialisations des journalistes. Ces projections sont apparues au long du travail empirique, depuis les focus groups visant à présenter l’outil aux journalistes, jusqu’aux entretiens orientés vers une prise en main plus approfondie. Les catégories ne sont pas exclusives : elles visent à rendre compte du travail interprétatif des journalistes qui consiste à isoler une série de manipulations clés (paramètres, structure globale du réseau) dans le but de s'approprier l'outil.
Chercher des sources et contacts
Une première catégorie d’usages se réfère à la recherche de contacts. Ceux dont il est question ici ne concernent pas forcément d’autres journalistes (réseautage), mais des personnes qui pourraient être potentiellement sollicitées comme sources ou invitées à des émissions. A priori, cet usage paraît éloigné de la cartographie de controverses pour laquelle le logiciel a été initialement conçu. Toutefois, les entretiens font apparaître de fortes attentes pour explorer le profil et les activités de comptes minoritaires disposant d’une certaine audience et qui pourraient être interrogés à ce titre dans des contenus journalistiques. L’objectif poursuivi est de repérer des utilisateurs qui s'expriment sur des thématiques, mais qui pourraient échapper à la veille informationnelle des journalistes. Cet usage a notamment été évoqué pour diversifier les profils des experts, tant du point de vue du profil (âge, genre, catégorie socioprofessionnelle) que du niveau d’expertise des intervenants, comme l’affirme une journaliste au sujet de la production d’un podcast :
Pour moi le fait de choisir un utilisateur et puis d’avoir les thématiques sur lesquelles il tweete, moi je trouve ça hyper intéressant, ça nous donne une idée des thématiques sur lesquelles il s’exprime en ce moment […] ça c’est hyper pratique. […] Dans mon cas personnel, on va éviter d’inviter Samia Hurst ou Antoine Flahault[1], mais on va essayer d’aller dans la strate peut-être suivante de gens un peu moins connus, qui s’expriment moins mais qui s’intéressent au thème, c’est parfois difficile d’identifier des femmes ou des jeunes par exemple. (Entretien du 15/07/2021)
Dans le logiciel SAD, les utilisateurs qui émettent à la fois beaucoup de tweets et reçoivent le plus de retweets sont particulièrement visibles car leur taille dépend du nombre d’interactions qu’ils entretiennent avec les autres comptes de la cartographie. Parce qu’ils publient beaucoup et que leurs propos sont repris par d’autres, ces comptes apparaissent comme centraux au sein des communautés. On pourrait supposer qu’ils exercent une certaine « influence » sur les plus petits nœuds qui soit publient moins, soit sont moins retweetés – une analyse qualitative de ces comptes et de leurs discours serait nécessaire pour qualifier et confirmer l’hypothèse de cette influence. La spécificité de SAD est de faire apparaître ces comptes moins actifs, mais aussi de faire apparaître des comptes «pivots» reliant deux communautés. Ces nœuds de taille plus restreinte peuvent être utilisés pour alimenter une autre requête qui éliminera les plus gros comptes, correspondant souvent à des comptes de personnalités ou institutionnels déjà connus des journalistes. La logique ne consiste pas à cartographier un maximum d’acteurs qui participent à une discussion, mais à repérer des comptes similaires.
Cette démarche implique une sélection très réduite de comptes de départ. En l'occurrence, un seul compte a été choisi pour générer une première cartographie, celui de la bioéthicienne suisse Samia Hurst, dans le but de trouver d’autres experts à même de s’exprimer sur l’éthique médicale. Le paramètre à privilégier est celui définissant le nombre de boucles de l’échantillonnage (depth), qui permet d’étendre ou de restreindre la zone explorée autour du compte de départ. Le paramètre définissant la taille de la communauté peut aussi être augmenté dans le but d’éliminer les utilisateurs qui auraient trop peu échangé avec le compte initial.

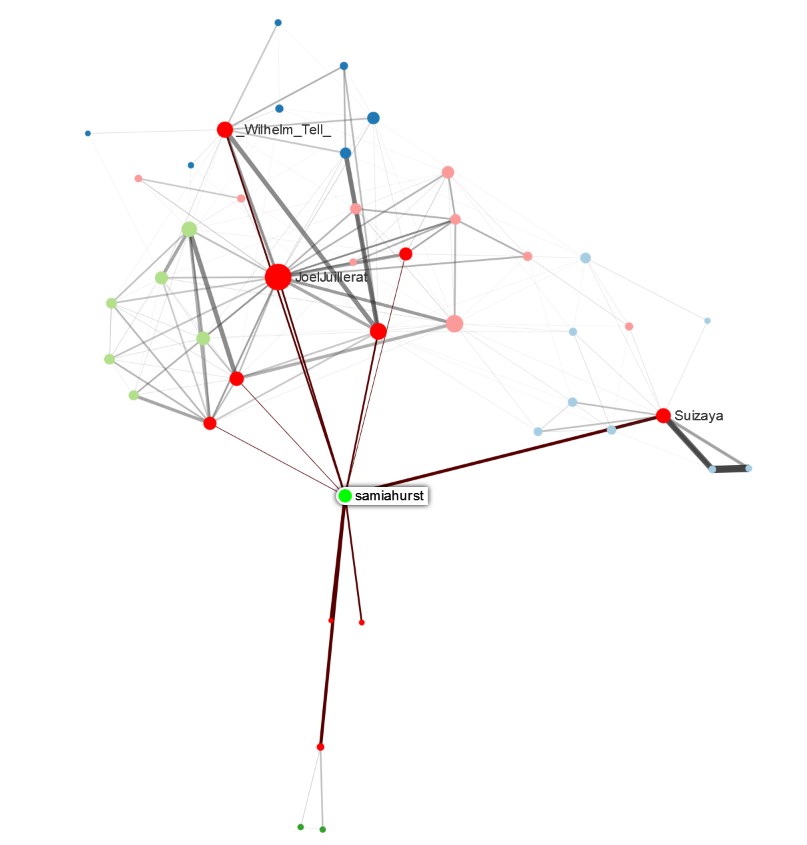
Figure 1 : Exemple de cartographie de données fondée sur la recherche de contacts et d'invités. Données récoltées le 15/07/2021.
Les cartographies réalisées dans le cadre de ces recherches de contacts ou d'invités sont particulièrement restreintes en raison du faible nombre de comptes initiaux et de leur homogénéité. Le travail interprétatif des données est facilité dans la mesure où le compte initial est facilement repérable. Les données jugées non pertinentes apparaissent de manière plus évidente que dans des cartographies élargies, ce qui facilite la formulation de requêtes plus fines. Dans la Figure 1, le groupe de nœuds verts à gauche du compte initial fait apparaître plusieurs comptes de journalistes, tandis que l'ensemble rouge fait apparaître des comptes institutionnels. Ce dernier pourrait faire l'objet d'une analyse qualitative de ses membres en vue d'identifier les comptes qui tweetent à propos du Ministre de la Santé suisse Alain Berset, présent dans cet ensemble. L'objectif de la journaliste étant ici de diversifier ses invités potentiels, d'autres comptes ont été ajoutés, certains institutionnels (experts, universitaires) et d'autres plus critiques, se présentant comme des vulgarisateurs scientifiques. En générant de nouvelles cartographies à partir de ces comptes, le compte de départ de Samia Hurst s'est effacé au profit d'autres correspondant davantage au profil recherché.
Parmi les 5 journalistes ayant participé aux focus group et entretiens, ce sont davantage ceux orientés vers les contenus audio qui ont privilégié cette approche. D’autres journalistes travaillant pour les contenus d’information télévisés ont également manifesté un intérêt pour cette utilisation dans le but de confronter des personnalités aux comptes avec lesquels ils ont le plus d’interactions.
Cartographier des controverses
Contrairement à la recherche de contacts, l’exploration de controverses vise à élargir au maximum la récolte de données pour identifier les groupes d’utilisateurs participant à la discussion. Le point de départ n’est pas un compte connu au préalable, mais une thématique autour de laquelle plusieurs utilisateurs sont identifiés comme étant actifs. Souvent, la thématique est déjà connue des journalistes car traitée par le média ou discutée en rédaction. Cet usage intervient notamment pour identifier si l’espace des discussions numériques sur Twitter présente des singularités, à travers les profils des participants ou encore la circulation d’un hashtag particulier. Lors d’un entretien, une journaliste travaillant pour une émission d’investigation de la RTS a souhaité explorer la diffusion d’une vidéo apparue dans sa veille du réseau social réalisée avec TweetDeck. Partagée massivement sous le hashtag « #Afriland », la vidéo remet en cause le témoignage de lanceurs d’alerte issus de la banque de République démocratique du Congo du même nom. Le réseau de comptes participant à sa diffusion a interpelé la journaliste puisque les tweets ne comprenaient rien d’autre que la vidéo, sans commentaire, ni discussion. Ses attentes portent sur la mise au jour de ce qui fonde ce réseau : « ce serait intéressant de voir s’ils sont connectés d’une façon ou d’une autre avec la banque, ou avec les avocats, enfin quel est le réseau autour duquel ils gravitent. » (Entretien du 16/07/2021). Ainsi, la cartographie apporte un contexte institutionnel voire idéologique pour qualifier la diffusion de (fausses) informations sur Twitter.
Cette approche cherche à élargir au maximum l’étendue des données, afin de diversifier les comptes et les types d’opinion qu’ils peuvent représenter. La probabilité d'échantillonnage (sampling probability) s’ajoute alors au critère de la profondeur évoqué précédemment, afin de ne pas submerger les journalistes d’un nombre de comptes trop important. En effet, ce paramètre de probabilité fixe un seuil de comptes (exprimé en pourcentage) à ne pas dépasser à chaque itération de la récolte par boule de neige dont le nombre augmente, par définition, à mesure qu’elle avance en profondeur. Ce paramètre est déterminant car il permet aux journalistes de prendre conscience que les données ne sont pas représentatives de l’ensemble du réseau social, mais d’une portion plus ou moins conséquente construite à l’aide de données récoltées en dehors de SAD (via la recherche avancée par exemple), grâce à l’API, et récoltées à l’aide d’un algorithme d'échantillonnage. L’exploration de controverses numériques repose sur le présupposé que les traces récoltées sont représentatives des opinions que représentent les comptes. Ainsi, les interactions (retweets et mentions) déterminent la taille des nœuds sur le graphique, ainsi que l’épaisseur des liens entre eux. Une manière d’affiner la récolte des données est donc d’intervenir sur le paramètre définissant le nombre minimal à partir duquel un utilisateur doit être mentionné par d’autres pour apparaître sur la cartographie (de façon à éliminer les interactions épisodiques par exemple).
Le tri des données s’effectue dans le volet de visualisation à l’aide notamment du « filtrage de communautés » qui permet d’isoler un ensemble de comptes du reste de la cartographie. Afin de pouvoir commenter ces données, les journalistes doivent aussi s’approprier la logique de représentation qui leur est proposée. La taille des nœuds est particulièrement importante puisqu’elle représente la propension des comptes à recevoir et émettre des interactions depuis et vers d’autres comptes, et donc à les situer dans le débat public. Dans le volet de visualisation, les paramètres in-degree et out-degree font varier la taille des nœuds en fonction du nombre d’interactions reçues ou émises, et renseignent donc sur le degré d’activité des comptes et leur rôle dans la controverse. Ainsi, des comptes de médias et de personnalités politiques tels que ceux d’Emmanuel Macron, d’Olivier Véran ou de BFM TV peuvent apparaître particulièrement importants parce qu’ils sont cités par d’autres, mais voir leur taille fortement réduite lorsque l’on s’intéresse à l’émission de likes et de retweets vers d’autres comptes.

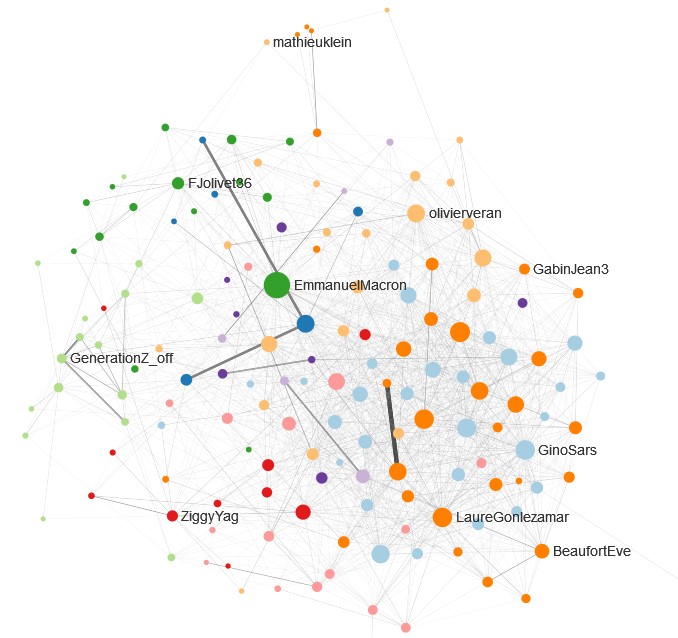
Figure 2 : Exemple de visualisation représentant la diversité des comptes prenant par à une controverse en ligne (ici, le hashtag #NousSavons rassemblant des points de vue « sceptiques » pendant la crise du Covid-19 en France). Données récoltées le 14/07/2021.
Du côté des journalistes, l’exploration de controverses est parfois envisagée à des fins illustratives, pour produire un instantané du débat public sur Twitter. Le plus souvent, elle sert de base pour explorer une communauté particulière en utilisant quelques comptes comme point de départ à une nouvelle recherche. Par exemple, les comptes opposés aux mesures sanitaires en Suisse ont été isolés pour générer une nouvelle cartographie. Ce type d’usage repose sur une analyse qualitative menée à partir des connexions entre comptes saisie comme un indicateur de leur positionnement idéologique dans le débat public sur Twitter. Afin de replacer les données dans le contexte de production des utilisateurs, un bouton génère automatiquement une requête dans la recherche avancée de Twitter, montrant les derniers tweets des comptes appartenant à un même groupe. De cette manière, les journalistes perçoivent les échanges à partir d’une sélection qu’ils ont eux-mêmes construite via l’API de Twitter, et non sur la base de leur timeline personnelle comme ils en ont l’habitude.
Les journalistes qui s’emparent de la visualisation de controverses envisagent d’explorer des sujets sur des périodes de temps délimitées. S’ils déclarent s’intéresser à des débats « chauds » qui se cristallisent autour de hashtags, plusieurs d’entre eux souhaitent également explorer des sujets qu’ils ont déjà traités dans le passé pour observer des rebonds ou de nouveaux développements. Dans tous les cas, les interrogés envisagent d’intégrer les données à leurs productions journalistiques, en publiant une version interactive de la cartographie ou en intégrant des tweets identifiés comme étant pertinents à l’égard de la thématique.
Mener l'enquête sur les réseaux socionumériques
Enfin, une troisième catégorie d’usages consacrée à la conduite d’enquêtes est apparue dans les échanges. Plus minoritaire en termes strictement quantitatifs, cette catégorie envisage la cartographie de données et son interprétation sous un angle complémentaire aux deux autres. Si la recherche de contacts aborde la cartographie comme un réseau social et l’exploration de controverses comme un réseau d’opinions sur une thématique, l’enquête interprète les connexions entre comptes selon des intérêts plus ou moins partagés. Ceux-ci peuvent être d’ordre économique, stratégique, diplomatique ou industriel. L’objectif est d’identifier les connexions directes entre des comptes et d’explorer leurs ramifications, comme l’explique un journaliste spécialiste des techniques d’OSINT :
Ce qui m’intéresse c’est plus un petit réseau, les vrais contacts, voir qui est ami avec qui, ou qui interagit directement, après dans une optique de type campagne politique, comment est amplifié un sujet, ou des choses comme ça, ça m’intéresse aussi, si un jour je pouvais dire, […] d’un sujet qui deviendrait mainstream, mais pour qui on pourrait montrer qu'il a été alimenté par un réseau politique X, ça m’intéresse aussi. (Entretien du 26/07/2021)
Sur le plan du paramétrage de l’outil, cette approche peut être considérée comme une combinaison des deux précédentes. En effet, il s’agit à la fois d’élargir au maximum le réseau et de resserrer la cartographie autour d’une sélection très stricte de comptes. Puisqu’elles visent à saisir des liens entre des acteurs précis qui ne sont pas nécessairement des personnalités publiques, les cartographies sont particulièrement minimales. Dans cette approche, les comptes initiaux sont parfaitement connus par le journaliste puisqu'issus d’une enquête initiée en amont et portant précisément sur les liens entre des acteurs et leurs institutions. Le logiciel SAD sert non seulement à repérer des comptes, mais aussi à qualifier ce qui les relie entre eux.
La présentation de ces trois scénarios d’usage permet de rendre compte de la diversité des modalités d’utilisation possible de l’outil dans un contexte de production journalistique. Comme cela a été mentionné, ces catégories ne sont pas monolithiques ni figées ; elles donnent plutôt lieu à des combinaisons et superpositions d’usages favorisant des appropriations multiples et différenciées. Elles conduisent in fine à reconsidérer le rapport des journalistes aux données et aux RSN.
Repenser le rapport des journalistes aux traces numériques
Au-delà de l’outil développé et des techniques employées, ce retour d'expérience de recherche pluridisciplinaire interroge la place des RSN dans les pratiques des journalistes ainsi que leur rapport aux traces, dans une démarche qui dépasse la simple promotion de contenus. Il s’agit en effet de penser et d’accompagner l’exploration d’un réseau comme Twitter à des fins de repérage (d’informations, de sources voire de controverses), mais aussi d’enquête prenant pour terrain d’investigation les traces numériques. Le développement et la diffusion de controverses en ligne peinent toutefois encore à être identifiés comme une arène publique nécessitant et méritant une attention à part entière chez les journalistes. Les freins que nous avons pu identifier sont multiples, mais c'est surtout la méconnaissance des structures de données qui empêche la compréhension des significations des cartographies produites et donc l’intérêt d'investiguer le numérique en tant qu'arène autonome et non pour compléter des observations faites dans les arènes plus traditionnelles du débat public.
Même s'il produit de l’information supplémentaire aux données initialement produites et visibles dans les plateformes numériques, l'outil SAD ne peut pas modifier à lui seul les pratiques des journalistiques. Cependant, il est en capacité de s’intégrer à ces dernières en permettant une diversification des sources et un accès facilité aux données et à leur interprétation. A contrario, forcer l'utilisation de ce type d’interface, sans l'accompagnement de l'équipe de recherche interdisciplinaire retracé dans cet article, peut entraîner un risque de sur- (voire de més-) interprétation des données et des visualisations. A travers la documentation de cette démarche de recherche appliquée à la croisée des journalism studies et des sciences des réseaux, nous avons voulu montrer que la conception d’un logiciel avec des représentants de ses futurs usagers contribue à penser l’autonomie de ces derniers dans les différentes phases du processus. Cette réflexion s'opère notamment à travers la reproductibilité des opérations par les journalistes et leur partage à des fins de publication.
Toutefois un enjeu de taille demeure : comment garantir une pleine autonomie d’usage, en particulier auprès de journalistes dont la culture numérique est superficielle ou partielle ? Comment favoriser une appropriation de la technologie, en dehors du cadre des échanges avec l'équipe de recherche jusque-là très présente ? En effet, les derniers échanges avec les journalistes s’orientent vers la conduite de projets éditoriaux qui reposent encore sur une présence très forte des chercheurs. Si le choix méthodologique de conduire des focus groups et entretiens auprès d’un petit nombre de journalistes a permis d’explorer en profondeur les usages possibles, leur généralisation n’en reste pas moins une étape cruciale et potentiellement problématique. Elle nécessiterait de déployer des moyens spécifiques de formation et de médiation pour favoriser l’accompagnement des usages en vue d’une utilisation complètement autonome. Dans sa dernière phase en cours, le projet a intégré une approche didactique visant notamment à expliciter autant que possible les différents paramètres et fonctionnalités de l’outil dans l’interface pour en faciliter la prise en main à plus large échelle (des fenêtres popup ont été envisagées). L’effort didactique a également porté sur la mise en évidence de son utilité dans la démarche journalistique, afin de sensibiliser les professionnels à l’investigation sur les réseaux sociaux. Enfin, les échanges autour de l’outil avec des journalistes de la RTS ont fait apparaître l’intérêt de disposer de « relais » au sein des équipes, c’est-à-dire de personnes qui, par leur expertise reconnue, pourront favoriser la découverte et l’intérêt pour la technologie proposée. La collaboration avec d’autres types de profils, notamment des recherchistes est actuellement explorée.
Ces réflexions sur l’appropriation effective de l’outil par les usagers représentent un enjeu éthique central, soulevé par la perspective d’une exploitation des données numériques dans un cadre d’usage qui dépasse celui d’une recherche avec des spécialistes du domaine de la cartographie des réseaux et de leur interprétation. En effet, l’utilisation du logiciel SAD repose aujourd’hui sur la collaboration entre l’équipe pluridisciplinaire de recherche et les journalistes et la poursuite du projet vise à favoriser l’appropriation de l’outil au sein du média partenaire. Cela questionne aussi en creux l'aboutissement de projets de recherche à finalité appliquée, ainsi que la diffusion des résultats (et les potentiels freins qu'ils peuvent générer) dans les milieux professionnels et académiques.
Bibliographie
Ahmad, A. N. (2010). Is Twitter a useful tool for journalists? Journal of Media Practice, 11(2), 145‑155. doi: 10.1386/jmpr.11.2.145_1
Bachimont, B. (2017). Le numérique comme milieu : enjeux épistémologiques et phénoménologiques. Principes pour une science des données. Interfaces numériques 4(3). doi: 10.25965/interfaces-numériques.386.
Bane, K. C. (2019). Tweeting the Agenda : How print and alternative web-only news organizations use Twitter as a source. Journalism Practice, 13(2), 191‑205. doi: 10.1080/17512786.2017.1413587
Bottini, T., et Julliard, V. (2017). Entre informatique et sémiotique. Réseaux, 204(4), 35-69. doi: 10.3917/res.204.0033.
Brandtzaeg, P. B., Følstad, A., et Chaparro Domínguez, M. Á. (2018). How Journalists and Social Media Users Perceive Online Fact-Checking and Verification Services. Journalism Practice, 12(9), 1109‑1129. doi: 10.1080/17512786.2017.136365
Brandtzaeg, P. B., Lüders, M., Spangenberg, J., Rath-Wiggins, L., et Følstad, A. (2016). Emerging Journalistic Verification Practices Concerning Social Media. Journalism Practice, 10(3), 323‑342. doi: 10.1080/17512786.2015.1020331
Broersma, M., et Graham, T. (2013). Twitter as a News Source. Journalism Practice, 7(4), 446‑464. doi: 10.1080/17512786.2013.802481
Broersma, M., et Graham, T. (2012). Social Media as Beat. Journalism Practice, 6(3), 403‑419. doi: 10.1080/17512786.2012.663626
Bruns, A. (ed.) (2018). Gatewatching and News Curation: Journalism, Social Media, and the Public Sphere. New York : Peter Lang.
Domingos, P. (2012). « A few useful things to know about machine learning ». Communications of the ACM 55.10: 78-87.
Flichy, P. (2003). L'innovation technique. Récents développements en sciences sociales. Vers une nouvelle théorie de l'innovation. Paris : La Découverte.
Gibson, E. J. (2000). Where is the information for affordances ? Ecological Psychology, vol.12, no 1, 53-56.
Illenberger, J., et Flötteröd, G. (2012). Estimating network properties from snowball sampled data. Social Networks, 34(4), 701-711. doi: 10.1016/j.socnet.2012.09.001.
Jacomy, M., Venturini, T., Heymann, S. et Bastian, M. (2014) ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. PLoS ONE. 9(6). doi: 10.1371/journal.pone.0098679.
Lariscy, R. W., Avery, E. J., Sweetser, K. D., et Howes, P. (2009). An examination of the role of online social media in journalists’ source mix. Public Relations Review, 35(3), 314‑316. doi: 10.1016/j.pubrev.2009.05.008.
Lawrence, R. G. (2015). Campaign News in the Time of Twitter. In : V. A., Farrar-Meyers et J. S. Vaughn (dir.), Controlling the Message: New Media in American Political Campaigns. New York, New York University Press. 93-112.
Lebart, L. (1994). Sur les analyses statistiques de texte. Journal de la société statistique de Paris. vol. 135, no 1, 17-36.
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., et Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM Computing Surveys (CSUR), 54(6), 1-35. doi: 10.1145/3457607
Mercier, A. (2013). Twitter l’actualité : Usages et réseautage chez les journalistes français. Recherches en Communication, 39, 111‑132. doi: 10.14428/rec.v39i39.49643.
Merzeau, L. 2013. « L’intelligence des traces ». Intellectica, 1(59) : 115-135. Repéré à https://halshs.archives-ouvertes.fr/halshs-01071211/document
Ratinaud, P. (2014). Documentation IRaMuTeQ. Repéré à http://iramuteq.org/documentation/fichiers/documentation_19_02_2014.pdf
Ricaud, B., Aspert, N., et Miz, V. (2020). Spikyball sampling: Exploring large networks via an inhomogeneous filtered diffusion. Algorithms, 13(11). Repéré à https://arxiv.org/abs/2010.11786.
Verlaet, L. (2015). La deuxième révolution des systèmes d’information : vers le constructivisme numérique. Hermès, 71(2), 249-254.
Weaver, D. H., Willnat, L., et Wilhoit, G. C. (2019). The American Journalist in the Digital Age: Another Look at U.S. News People. Journalism & Mass Communication Quarterly, 96(1), 101‑130. doi: 10.1177/1077699018778242
Notes
[1] Respectivement bioéthicienne et épidémiologiste suisses.